08 Aug 2024
CMU 15-445 notes: Storage Models & Compression
This is a personal note for the CMU 15-445 L5 notes.
1. Database workloads
1.1. OLTP (Online Transaction Processing)
- Characterized by fast, repetitive, simple queries that operator on a small amount of data, e.g., a user adds an item to its Amazon cart and pay.
- Usually more writes than read.
1.2. OLAP (Online Analytical Processing)
- Characterized by complex read queries on large data.
- E.g., compute the most popular item in a period.
1.3. HTAP (Hybrid)
- OLTP + OLAP.
2. Storage models
- Different ways to store tuples in pages.
2.1. N-ary Storage Model (NSM)
- Store all attributes for a single tuple contiguously in a single page, e.g., slotted pages.
- Pros: good for queries that need the entire tuple, e.g., OLTP.
- Cons: inefficient for scanning large data with a few attributes, e.g., OLAP.
2.2. Decomposition Storage Model (DSM)
- Store each attribute for all tuples contiguously in a block of data, i.e., column store.
- Pros: save I/O; better data compression; ideal for bulk single attribute queries like OLAP.
- Cons: slow for point queries due to tuple splitting, e.g., OLTP.
- 2 common ways to put back tuples:
- Most common: use fixed-length offsets, e.g., the value in a given column belong to the same tuple as the value in another column at the same offset.
- Less common: use embedded tuple ids, e.g., each attribute is associated with the tuple id, and the DBMS stores a mapping to jump to any attribute with the given tuple id.
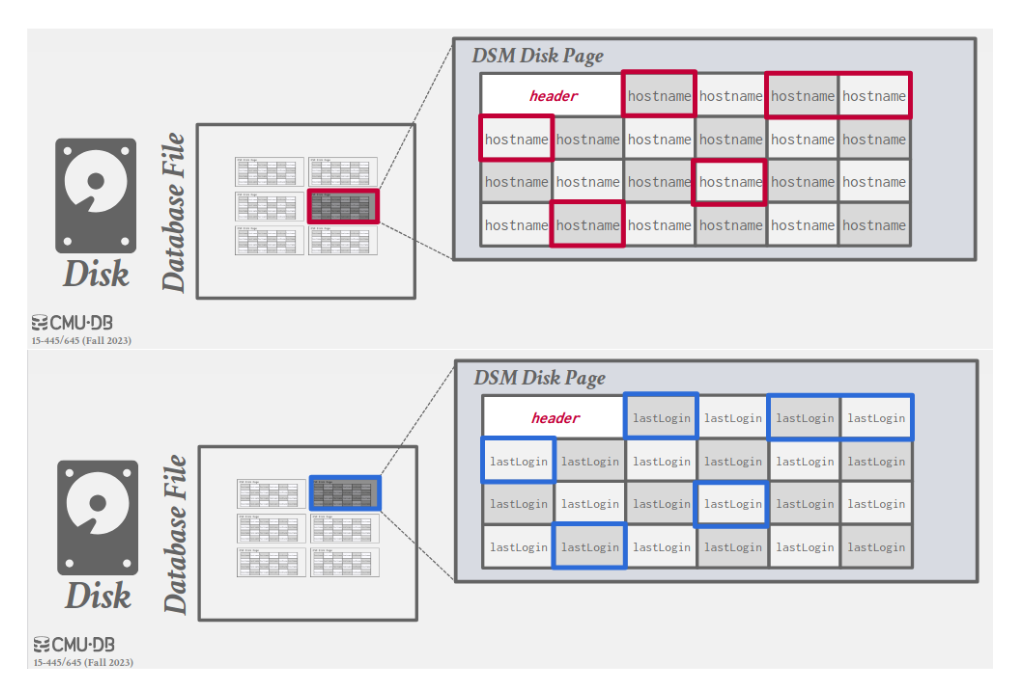
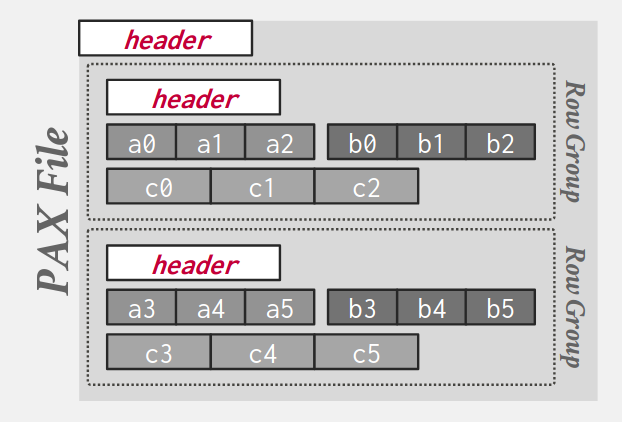
2.3. Partition Attributes Across (PAX)
- Rows are horizontally partitioned into groups of rows; each row group uses a column store.
- A PAX file has a global header containing a directory with each row group’s offset; each row group maintains its own header with content metadata.
3. Database compression
- Disk I/O is always the main bottleneck; read-only analytical workloads are popular; compression in advance allows for more I/O throughput.
- Real-world data sets have the following properties for compression:
- Highly skewed distributions for attribute values.
- High correlation between attributes of the same tuple, e.g., zip code to city.
- Requirements on the database compression:
- Fixed-length values to follow word-alignment; variable length data stored in separate mappings.
- Postpone decompression as long as possible during query execution, i.e., late materialization.
- Lossless; any lossy compression can only be performed at the application level.
3.1. Compression granularity
- Block level: compress all tuples for the same table.
- Tuple level: compress each tuple (NSM only).
- Attribute level: compress one or multiple values within one tuple.
- Columnar level: compress one or multiple columns across multiple tuples (DSM only).
3.2. Naive compression
- Engineers often use a general purpose compression algorithm with lower compression ratio in exchange for faster compression/decompression.
- E.g., compress disk pages by padding them to a power of 2KBs and storing them in the buffer pool.
- Why small chunk: must decompress before reading/writing the data every time, hence need o limit the compression scope.
- Does not consider the high-level data semantics, thus cannot utilize late materialization.
4. Columnar compression
- Works best with OLAP, may need additional support for writes.
4.1. Dictionary encoding
- The most common database compression scheme, support late materialization.
- Replace frequent value patterns with smaller codes, and use a dictionary to map codes to their original values.
- Need to support fast encoding and decoding, so hash function is impossible.
- Need to support order-preserving encodings, i.e., sorting codes in the same order as original values, to support range queries.
- E.g., when
SELECT DISTINCTwith pattern-matching, the DBMS only needs to scan the encoding dictionary (but withoutDISTINCTit still needs to scan the whole column).
- E.g., when
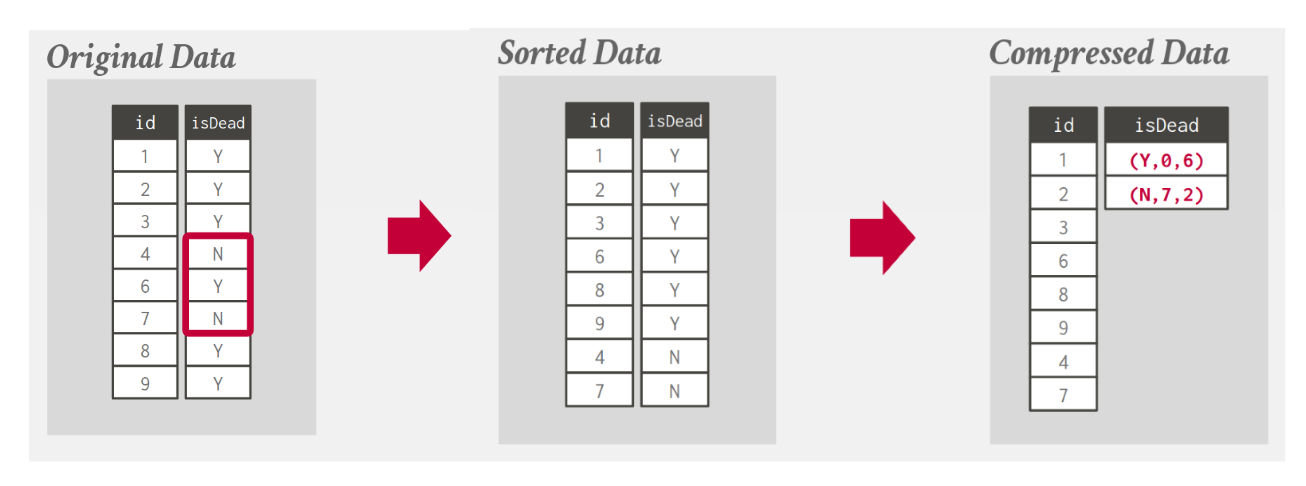
4.2. Run-Length encoding (RLE)
- Compress runs (consecutive instances) of the same value in a column into triplets
(value, offset, length). - Need to cluster same column values to maximize the compression.
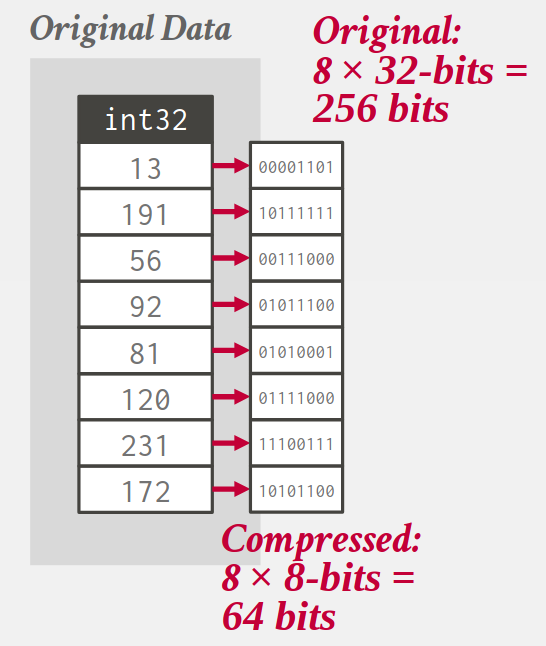
4.3. Bit-packing encoding
- Use less bits to store an attribute.
4.4. Mostly encoding
- Use a special marker to indicate values that exceed the bit size and maintains a look-up table to store them.

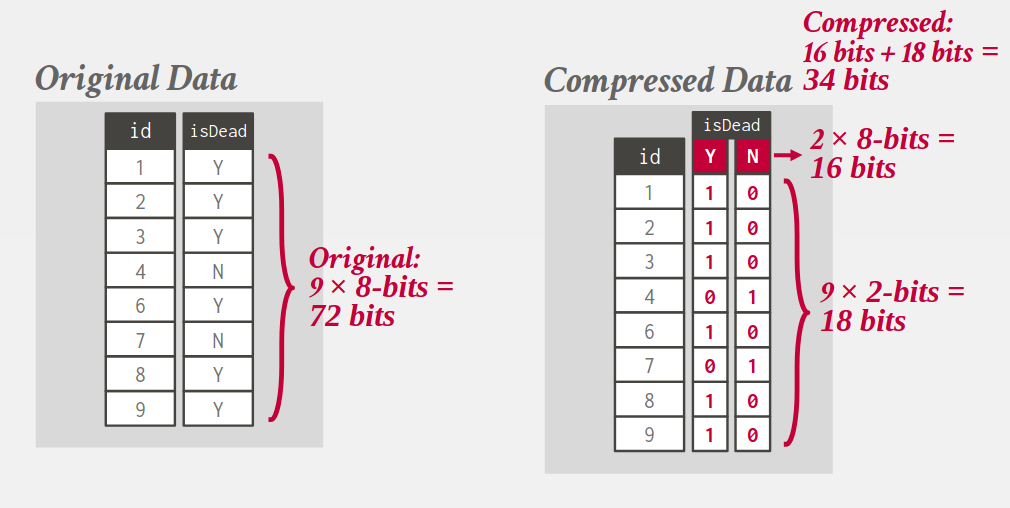
4.5. Bitmap (One-hot) encoding
- Only practical if the value cardinality is low.
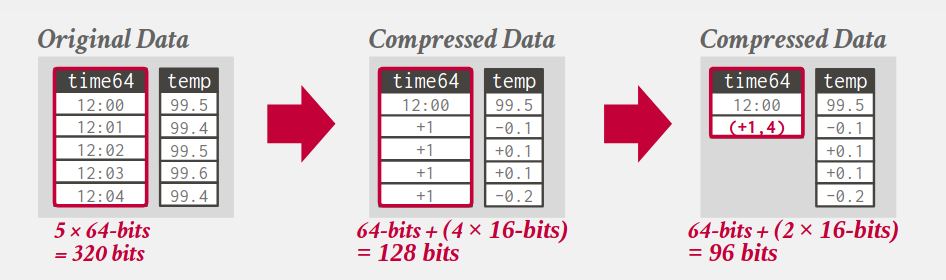
4.6. Delta encoding
- Record the difference between values; the base value can be stored in-line or in a separate look-up table.
- Can be combined with RLE encoding.
4.7. Incremental encoding
- Common prefixes or suffixes and their lengths are recorded to avoid duplication.
- Need to sort the data first.