Posts tagged "software":
23 Oct 2024
Book notes: A Philosophy of Software Design
This is a personal note for the book “A Philosophy of Software Design” (2018, John Ousterhout). John Ousterhout is the author of Tcl scripting language and the Raft protocol. This book works together with Stanford CS190.
1. Introduction
- The most fundamental problem in CS is problem decomposition: how to divide a complex problem into pieces that can be solved independently.
- Complexity increases inevitably over the life of the program, but simpler designs allow to build larger systems before complexity becomes overwhelming.
- Two general approaches:
- Making code more obvious, e.g., eliminating special cases, using identifiers in a consistent fashion.
- Encapsulate the complexity, i.e., divide a system into independent modules.
- Waterfall model: each phase of a project e.g., requirement, design, coding, testing, completes before the next phase starts, such that the entire system is designed once.
- Does not work for software since the problem of the initial design do not become apparent until implementation is well underway; then the developers need to patch around the problems, resulting in an explosion of complexity.
- Agile/Incremental development: in each iteration the design focuses on a small subset of the overall functionality, so that problems can be fixed when the system is small and later features benefit from previous experience.
- Developers should always think about design issues and complexity, and use complexity to guide the design.
2. Complexity
- Complexity is incremental.
- Developers must adopt a zero tolerance philosophy.
2.1. Definition
- Complexity is anything related to the structure of a software system that makes it hard to understand and modify the system.
- \(C = \sum_p(c_pt_p)\): The overall complexity is determined by the complexity of each part \(p\) weighted by the fraction of time developers working on that part.
- Isolating complexity in a place where it will never be seen is as good as eliminating the complexity.
- Complexity is more apparent to readers than writers: if you write a piece of code that seems simple to you, but others think it is complex, then it is complex.
2.2. Symptoms
- Change amplification: a seemingly simple change requires code modifications in many different places.
- Cognitive load: developers have to spend more time learning the required information to complete a task, which leads to greater risk of bugs.
- E.g., a function allocates memory and returns a pointer to the memory, but assumes the caller should free the memory.
- Sometimes an approach that requires more lines of code is actually simpler as it reduces cognitive load.
- Unknown unknowns (the worst!): it is not obvious which pieces of code must be modified or which information must have to complete the task.
- The goal of a good design is for a system to be obvious: a developer can make a quick guess about what to do and yet to be confident that the guess is correct.
2.3. Causes
- Complexity is caused by two things: dependencies and obscurity.
- A dependency exists when a code cannot be understood and modified in isolation.
- E.g., in network protocols both senders and receivers must conform to the protocol, changing code for the sender almost always requires corresponding changes at the receiver.
- Dependencies are fundamental and cannot be completely eliminated, the goal is to make the dependencies remain simple and obvious (e.g., variable renaming are detected by compilers).
- Obscurity occurs when important information is not obvious, e.g., a variable is too generic or the documentation is inadequate.
- Obscurity is often associated with non-obvious dependencies.
- Inconsistency is also a major contributor, e.g., the same variable name is used for two different purposes.
- The need for extensive documentation is often a red flag that the design is complex.
- Dependencies lead to change amplification and cognitive load; obscurity creates unknown unknowns and cognitive load.
3. Programming mindsets
- Tactical programming: the main focus is to get something working, e.g., a new feature or a bug fix.
- Tactical programming is short-sighted, e.g., each task contributes a reasonable compromise to finish the current task quickly.
- Once a code base turns to spaghetti, it is nearly impossible to fix.
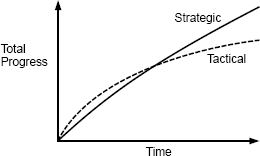
3.1. Strategic programming
- Requires an investment mindset to improve the system design rather than taking the fastest path to finish the current task.
- Proactive investment: try a couple of alternative designs and pick the cleanest one; imagine a few ways in which the system might need to be changed in the future; write documentation.
- Reactive investments: continuously make small improvements to the system design when a design problem becomes obvious rather than patching around it.
- The ideal design tends to emerge in bits and pieces, thus the best approach is to make lots of small investments on a continual basis, e.g., 10-20% of total development time on investments.
4. Modular design
- The goal of modular design is to minimize the dependencies between modules.
- Each module consists of two parts: interface and implementation. The interface describes what the module does, the implementation specifies how it does.
- The interface consists of everything that a developer working on a different module must know in order to use the given module.
- The implementation consists of the code that carries out the promises made by the interface.
- The best modules are deep, i.e., those whose interfaces are much simpler than their implementations.
- In such cases the modification in the implementation is less likely to affect other modules.
- Small modules tend to be shallow, because the benefit they provide is negated by the cost of learning and using their interfaces.
- Classitis refers to a mistaken view that developers should minimize the amount of functionality in each new class.
- It may result in classes that are individually simple, but increases the overall complexity.
4.1. Interface
- A module interface contains two information: formal and informal.
- The formal part for a method is its signature; The formal interface for a class consists of the signatures for all public methods and variables.
- The informal part includes its high-level behavior and usage constraints; they can only be described using comments and cannot be ensured by the programming languages.
- Informal aspects are larger and more complex than the formal aspects for most interfaces.
- While providing choice is good, interfaces should be designed to make the common case as simple as possible (c.f. \(C = \sum_p(c_pt_p)\)).
4.2. Abstraction
- An abstraction is a simplified view of an entity, which omits unimportant details.
- The more unimportant details that are omitted from an abstraction, the better, otherwise the abstraction increases the cognitive load.
- A detail can only be omitted if it is unimportant, otherwise obscurity occurs.
- In modular programming, each module provides an abstraction in form of its interface.
- The key to designing abstractions is to understand what is important.
- E.g., how to choose storage blocks for a file is unimportant to users, but the rules for flushing data to secondary storage is important for databases, hence it must be visible in the file system interface.
- Garbage collectors in Go and Java do not have interface at all.
5. Information hiding
- Information hiding is the most important technique for achieving deep modules.
- Each module should encapsulate a few design information (e.g., data structures, low-level details) in the module implementation but not appear in its interface.
- Information hiding simplifies the module interface and makes it easier to evolve the system as a design change related a hidden information only affects that module.
- Making an item
privateis not the same as information hiding, as the information about the private items can still be exposed through public methods such asgetterandsetter. - If a particular information is only needed by a few of a class’s users, it can be partially hidden if it is accessed through separate methods, so that it is still invisible in the most common use cases.
- E.g., modules should provide adequate defaults and only callers that want to override the default need to be aware of the parameter.
5.1. Information leakage
- The leakage occurs when a design decision is reflected in multiple modules. thus creating dependencies between the modules.
- Interface information is by definition has been leaked.
- Information can be leaked even if it does not appear in the interface, i.e., back-door leakage.
- E.g., two classes read and write the same file format, then if the format changes, both classes need to be modified; such leakage is more pernicious than interface leakage as it is not obvious.
- If affected classes are relatively small and closely tied to the leaked information, they may need to be merged into a single class.
- The bigger class is deeper as the entire computation is easier to be abstracted in the interface compared to separate sub-computations.
- One may also pull the leaked information out of all affected classes and create a new class to encapsulate the information, i.e., replace back-door leakage with interface leakage.
- One should avoid exposing internal data structures (e.g., return by reference) as such approach makes more work for callers, and make the module shallow.
- E.g., instead of writing
getParams()which returns a map of all parameters, one should havegetParameter(String name)andgetIntParameter(String name)to return a specific parameter and throw an exception if the name does not exist or cannot be converted.
- E.g., instead of writing
5.2. Temporal decomposition
- Temporal decomposition is a common cause of information leakage.
- It decompose the system into operations corresponding to the execution order.
- E.g., A file-reading application is broken into 3 classes: read, modify and write, then both reading and writing steps have knowledge about the file format.
- The solution is to combine the core mechanisms for reading and writing into a single class.
- Orders should not be reflected in the module structure unless different stages use totally different information.
- One should focus on the knowledge needed to perform each task, not the order in which tasks occur.
6. General-Purpose modules
- General-purpose modules can be used to address a broad range of problems such that it may find unanticipated uses in the future (cf. investment mindset).
- Special-purpose modules are specialized for today’s needs, and can be refactored to make it general-purpose when additional uses are required (cf. incremental software development).
- The author recommends a “somewhat general-purpose” fashion: the functionality should reflect the current needs, but the interface should be general enough to support multiple uses.
- The following questions can be asked to find the balance between general-purpose and special-purpose approach:
- What is the simplest interface that will cover all current needs?
- How many situations will a method be used?
- Is the API easy to use for the current needs (not go too far)?
6.1. Example: GUI text editor design
- Specialized design: use individual method in the text class to support each high-level features, e.g.,
backspace(Cursor cursor)deletes the character before the cursor;delete(Cursor cursor)deletes the character after the cursor;deleteSelection(Selection selection)deletes the selected section. - The specialized design creates a high cognitive load for the UI developers: the implementation ends up with a large number of shallow methods so a UI developer had to learn all of them.
- E.g.,
backspaceprovides a false abstraction as it does not hide the information about which character to delete.
- E.g.,
- The specialized design also creates information leakage: abstractions related to the UI such as backspace key and selection, are reflected in the text class, increasing the cognitive load for the text class developers.
- General-purpose design define API only in terms of basic text features without reflecting the higher-level operations.
- Only three methods are needed to modify a text:
insert(Position position, String newText),delete(Position start, Position end)andchangePosition(Position position, int numChars).- The new API uses a more generic
Positionto replace a specific user interfaceCursor. - The delete key can be implemented as
text.delete(cursor, text.ChangePosition(cursor, 1)), the backspace key can be implemented astext.delete(cursor, text.ChangePosition(cursor, -1)).
- The new API uses a more generic
- Only three methods are needed to modify a text:
- The new design is more obvious, e.g., the UI developer knows which character to delete from the interface, and also has less code overall.
- The general-purpose methods can also be used for new feature, e.g., search and replace text.
7. Layers of abstractions
- Software systems are composed into layers, where higher layers use the facilities provided by lower layers; each layer provides an abstraction different from the layers above or below it.
- E.g., a file in the uppermost layer is an array of bytes and is a memory cache of fixed-size disk blocks in the next lower layer.
- A system contains adjacent layers with similar abstractions is a red flag of class decomposition problem.
- The internal representations should be different from the abstractions that appear in the interface; if the interface and the implementation have similar abstractions, the class is shallow.
- It is more important for a module to have a simple interface than a simple implementation to benefit more user.
- Simple implementation example: throw an exception when don’t know how to handle the condition; define configuration parameters (developers should compute reasonable defaults automatically for configuration parameters).
- Simple interface example: make a text editor GUI character-oriented rather on line-oriented so users can insert and delete arbitrary ranges of text.
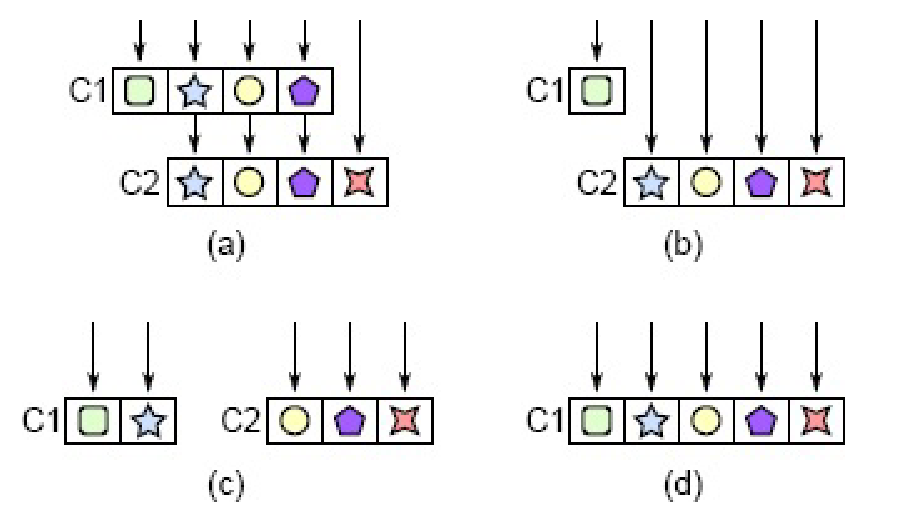
7.1. Pass-through methods
- A pass-through method is a method that does little except invoke another method, whose signature is similar or identical to the callee function.
- Pass-through methods usually indicates there is not a clean division of responsibility between classes.
- Pass-through methods also create dependencies between classes.
- The solution is to refactor the classes, e.g., expose the lower level class directly to the higher level (b), redistribute the functionality (c) or merge them (d):
7.2. Pass-through variables
- A pass-through variable is a variable that is passed down through a long chain of methods.
- Pass-through variables add complexity as all intermediate methods must be aware of the existence and need to be modified when a new variable is used.
- The author’s solution is to introduce a context object which stores all application’s global states, e.g., configuration options and timeout value, and there is one context object per system instance.
- To avoid passing through the context variable, a reference to the context can be saved in other objects.
- When a new object is created, the context reference is passed to the constructor.
- Contexts should be immutable to avoid thread-safety issues and may create non-obvious dependencies.
7.3. Acceptable interface duplication
- Dispatcher: a method that uses its arguments to select a specific method to invoke and passes most of its arguments.
- E.g., when a web server receives an HTTP request, it invokes a dispatcher to examine the URL and selects a specific method to handle the request.
- Polymorphous methods, e.g.,
len(string)andlen(array)reduces cognitive load; they are usally in the same layer and do not invoke each other. - Decorator: a wrapper that takes an existing object and extends its functionality.
- Decorators are often shallow and contain pass-through methods, one should consider following alternatives before using them:
- Add the new functionality directly to the class if it is relatively general-purpose; or merge it with the specific use case if it is specialized.
- Merge the new functionality with an existing decorator to make the existing decorator deeper.
- Implement it as a stand-alone class independent of the base class, e.g.,
WindowandScrollableWindow.
8. Combine or separate functionality
- The goal is to reduce the system complexity as a whole and improve its modularity.
- Subdividing components create additional complexity, e.g. additional code.
- Developers should separate one general-purpose code from special-purpose code, each special-purpose code should go in a different module, e.g., pull the special-purpose code into higher layers.
- A general-purpose mechanism provides interfaces for special-purpose code to override.
- Each special-purpose code implements particular logic which is unaware by other code, including the general-purpose mechanism.
- Combining codes is most beneficial if they are closely related:
- They share information, e.g., HTTP request reader and parser.
- They share repeated pattern, e.g., may
gotosame cleanup code. - The combination simplifies the interface, e.g., each code implement a part of the solution.
- They are used together bi-directionally, e.g., a specific error message which is only invoked by one method.
- They overlap conceptually in that there is single higher-level category including both code.
- Each method should do one thing and do it completely.
- The length itself is rarely a good reason for splitting up methods.
- If a method is subdivided, users should be able to understand the child method independently, which typically means the child method is relatively general-purpose, otherwise conjoined methods are created.
9. Exception handling
- Exceptions refer to any uncommon condition that alters the normal control flow.
- E.g., bad arguments, an I/O operation fails, server timeout, packet loss, unprepared condition.
- It’s difficult to ensure that exception handling code really works, especially in distributed data-intensive systems.
- Classes with lots of exceptions have complex interfaces and are shallow.
- The best way is to reduce the number of places where exceptions have to be handled.
- The author proposes 4 techniques: define errors out of existence; exception handling; exception aggregation; crash.
- For errors that are not worth trying to handle, or occur infrequently, abortion is the simplest thing to do; e.g., there is nothing the application can do when an out-of-memory exception occurs.
- Same as exceptions, special cases can result in code riddled with
ifstatements, they should be eliminated by designing the normal case in a way that automatically handles the special cases.
9.1. Define errors out of existence
- Example 1: instead of throwing an exception when a key does not exist in
remove, simply return to ensure the key no longer exists. - Example 2: instead of throwing an exception when trying to delete a file that is still open in other processes, mark the file for deletion to deny any processes open the old file later, and delete the file after all processed have closed the file.
- Example 3: instead of throwing an
IndexOutOfBoundsExeceptionwhensubstring(s, begin, end)takes out-of-range arguments, return the overlap substring.
9.2. Exception masking
- An exceptional condition is detected and handled at a low level in the system so that higher levels need not be aware of the condition.
- E.g., when a TCP packet is lost, the packet is resent within the implementation and clients are unaware of the dropped packets (they notice the hanging and can abort manually).
- Exception masking results in deeper classes and pulls complexity downward.
9.3. Exception aggregation
- Exception aggregation handles many special-purpose exceptions with a single general-purpose handler.
- Example 1: instead of catching the exception for each individual missing parameter, let the single top-level exception handler aggregate the error message with a single top-level try-catch block.
- The top-level handler encapsulates knowledge about how to generate error responses, but knows nothing about specific errors.
- Each service knows how to generate errors, but does not know how to send the response.
- Example 2: promote rare exceptions (e.g., corrupted files) to more common exceptions (e.g., server crashes) so that the same handler can be used.
10. Design it twice
- Rather than picking the first idea that comes to mind, try to pick several approaches that are radically different from each other.
- No need to pin down every feature of each alternative.
- Even if you are certain that there is only one reasonable approach, consider a second design anyway, no matter how bad it will be.
- It will be instructive to think about the weaknesses of the second design and contrast with other designs.
- It’s easier to identify the best approach if one can compare a few alternatives.
- Make a list of the pros and cons of each rough design, e.g.,
- Does one design have a simpler/ more general-purpose interface than another?
- Does one interface enable a more efficient implementation?
- The design-it-twice principle can be applied at many levels in a system, e.g., decompose into modules, pick an interface, design an implementation (simplicity and performance).
- No-one is good enough to get it right with their first try in large software system design.
- The process of devising and comparing multiple approaches teach one about the factors that make designs better or worse.
11. Write comments
11.1. Why write comments
- The correct process of writing comments will improve the system design.
- A significant amount of design information that was in the mind of the designer cannot be represented in code, e.g., the high-level description of a method, the motivation for a particular design.
- Comments are fundamental to abstractions: if users must read the code to use it, then there is no abstraction.
- If there is no comment, the only abstraction of a method is its declaration which misses too much essential information to provide a useful abstraction by itself; e.g., whether
endis inclusive.
- If there is no comment, the only abstraction of a method is its declaration which misses too much essential information to provide a useful abstraction by itself; e.g., whether
- Good comments reduce cognitive load and unknown unknowns.
11.2. What are good comments
- Follow the comment conventions, e.g., Doxygen for C++, godoc for Go.
- Comments categories:
- Interface: a comment block that precedes the declaration; describes the interface, e.g., overall behavior or abstraction, arguments, return values, side effects or exceptions and any requirements the caller must satisfy.
- Data structure member: a comment next to the declaration of a field in a data structure, e.g., a variable.
- Implementation comment: a comment inside the code to describe how the code work internally.
- Cross-module comment: a comment describing dependencies that cross module boundaries.
- The interface and the data structure member comments are the most important and should be always present.
- Don’t repeat the code: if someone who has never seen the code can also write the comment by just looking at the code next to the comment, then the comment has no value.
- Don’t use the same words in the comment that appear in the name of the entity being described, pick words that provide additional information.
- Comments should augment the code by providing information at a different level of detail.
- Lower-level: add precision by clarifying the exact meaning of the code.
- Higher-level: offer intuition behind the code.
11.2.1. Lower-level comments
- Precision is most useful when commenting variable declarations.
- Missing details include: variable units; boundary conditions (inclusive/exclusive); whether a null value is permitted and what does it imply; who is responsible for a resource release; variable invariants that always true.
- Avoid vague comments, e.g., “current”, not explicitly state the keys and values in a map.
- Comments on a variable focuses on what the variable represents, not how it will be modified.
- E.g., instead of documenting when a boolean variable is toggled to true/false, document what true/false mean.
11.2.2. Higher-level comments
- Help the reader understand the overall intent and code structure, usually inside the code.
- More difficult to write than lower-level comments as one must think about the code in a different way.
- Comments can include why we need this code; what the code does on a high-level.
11.2.3. Interface comments
- Separate interface comments from implementation comments: interface comments provide information for someone to use rather than maintain the entity.
- A class interface comment documents the overall capability and limitation of a class and what each instance represents.
- A method interface comment include both higher-level and lower-level information.
- Starts with one or two sentences describing the method behavior and performance (e.g., whether concurrently).
- Must be very precise about each argument and the return value, and must mention any constraint and dependencies on the arguments.
- Must document any side effects that affect the system future behavior, e.g., modify a system data structure which can be read by other methods.
- Must document any preconditions that must be satisfied before a method is invoked.
11.2.4. Implementation comments
- The main goal is to help readers understand what the code is doing and why the code is needed (e.g., refer to a bug report), not how.
- For long methods, add a comment before each of the major blocks to provide a abstract description of what the block does.
- For complex loops, add a comment before the loop to describe what happens in each iteration at an intuitive level.
- Document the local variables if they are used over a large span of code.
11.2.5. Cross-module comments
- Real systems involve design decisions that affect multiple classes.
- The biggest challenge of documenting cross-module decisions is to find a place.
- E.g., when a new state is introduced, multiple updates are required to handle the state; an obvious place to document all required updates is inside the state enum where a new state will be added.
- When there is no obvious place, e.g., all updates depend on each other, the author recommends documenting them in a central design notes.
- The file is divided up into clearly labeled section, one for each major topic.
- Then in any code that relates to a topic, add a short comment “see ”X“ in designNotes”.
- The disadvantage of this approach is to keep is up-to-date as the system envolves.
12. Choose names
- A good name conveys information about what the underlying entity is and is not.
- Ask yourself: if someone sees this name in isolation without seeing its declaration or documentation, how closely can they guess?
- A good name has two properties: precision and consistency.
- The greater the distance between a name’s declaration and its last usage, the longer the name should be.
12.1. Precision
- Vague name examples: “count”, “status”, “x”, “result” in a no return method.
- It’s fine to use generic “i/j” in a loop as long as the loop does not span large.
- A name may also become too specific, e.g.,
delete(Range Selection)suggests the argument must be a selection, but it can also be passed with unselected range. - If you find it difficult to come up with a name that is precise, intuitive and not too long, then it is a red flag that the variable may not have a clear design.
- Consider alternative factorings, e.g., separate the representation into multiple variables.
12.2. Consistency
- Always use the common name for and only for the given purpose, e.g.,
chfor a channel. - Make sure the purpose is narrow enough that all variables with the same name have the same behavior.
- E.g., a
blockpurpose is not narrow as it can have different behaviors for physical and logical blocks.
- E.g., a
- When you need multiple variables that refer to the same general thing, use the common name for each variable and add a distinguishing prefix, e.g.,
srcBlockanddstBlock. - Always use
iin outmost loops andjfor nested loops.