24 Jul 2024
Parallel EVM: Reth scaling plan
This is a personal note for Reth-performance-blog as well as some terminology explain online, e.g., Reth-repo and Claude.ai.
1. Blockchain fundamentals
1.1. Ethereum engine API
- A collection of JSON-RPC methods that all execution clients implement.
- Specify the interfaces between consensus and execution layers.
1.2. Foundry
- A Rust-written toolkit for Ethereum application development.
- Consists of an Ethereum testing framework Forge; a framework to interact with the chain Cast; a local Ethereum node Anvil; and a Solidity REPL (Read-Eval-Print-Loop: an interactive environment) Chisel.
1.3. Revm
- A Rust-written EVM; responsible for executing transactions and contracts.
1.4. Alloy
- A library to interact with the Ethereum and other EVM-base chains.
1.5. Erigon & Staged sync
- Erigon: a Go-written Ethereum client implementation (execution layer).
- Staged sync: break the chain synchronization process into distinct stages in order to achieve better efficiency.
1.6. Storage engines
1.6.1. ACID
- A set of properties for database transactions: atomicity, consistency, isolation, duration.
- Atomicity: a transaction is treated as an indivisible unit; if any part of the transaction fails, the entire transaction is rolled back.
- Consistency: a transaction brings the database from one valid state to another.
- Isolation: concurrent transaction execution leave the database in the same state as if transactions are executed sequentially
- Duration: a committed transaction remains committed even when the system fails.
1.6.2. MVCC (Multi-version concurrency control)
- A concurrency control model used in DBMS.
- MVCC keeps multiple version of data simultaneously, each transaction sees a snapshot of the database.
1.6.3. Common database models
- Relational model, e.g., SQL.
- Document model.
- Network model.
- key-value, e.g., NoSQL.
1.6.4. Common storage engines
- MDBX: Ultra-fate key-value embedded database with ACID and MVCC supported.
- LevelDB: Google-developed key-value store using log-structured merge-tree for high write throughput.
- RocksDB: Meta’s fork of LevelDB, optimized for fast storage.
- LSM-based DBs, e.g., BadgerDB: optimized for write-heavy workloads with log-structured merge-tree.
- BoltDB: Go-written key-value database with optimized B+ tree, ACID supported.
- LMDB: memory-mapped key-value store with ACID and MVCC supported.
1.7. Reth
- A Rust implementation of an Ethereum full node; allows users to interact with the Ethereum blockchain.
- An execution layer that implements all Ethereum engine APIs.
- Modularity: every component is built as a library.
- Performance: uses Erigon staged-sync node architecture and other Rust libraries (e.g., Alloy, revm); tests and optimizes on Foundry.
- Database/Storage engine: MDBX.
1.8. Why gas per second as the performance metric
- More nuanced than TPS.
- Allows for a clear understanding for the capacity and efficiency.
- Helps assessing the cost implications, e.g., DoS attacks.
1.9. EVM cost models
- Determines the computational and storage costs for the execution.
- Key aspects: gas, gas cost (for each operation), gas price (in Wei), gas limit.
1.10. TPC benchmark
- Standardized performance tests for transaction processing and databases, e.g., how many transactions a system can process in a given period.
- Offer benchmarks for different scenarios, e.g., TPC-C for online transaction processing.
1.11. State growth
- State: the set of data for building and validating new Ethereum blocks.
- State growth: the accumulation of new account and new contract storage.
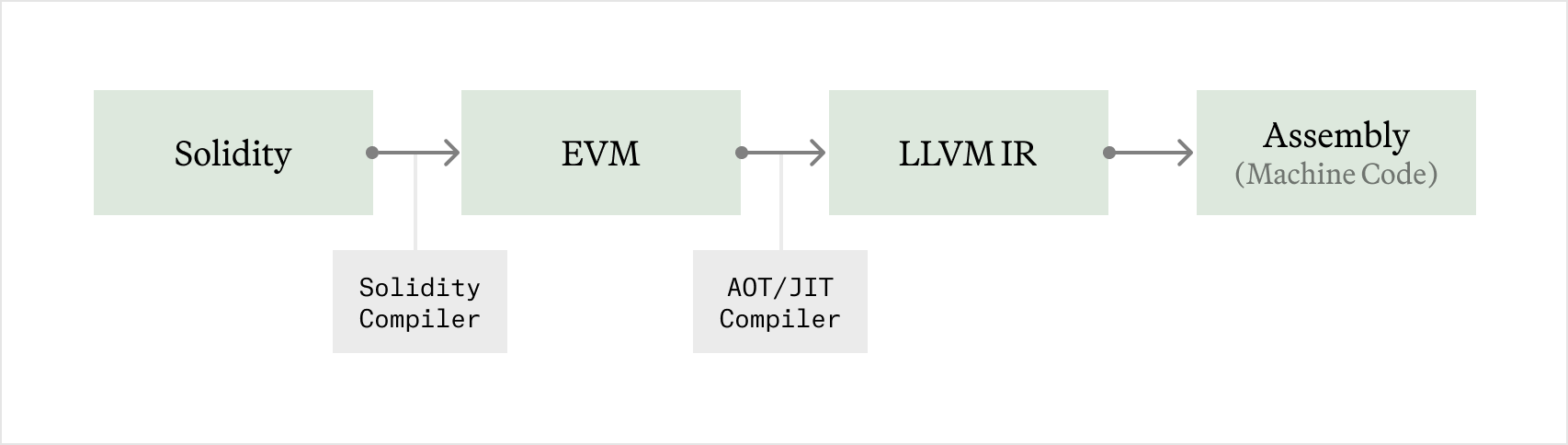
1.12. JIT (Just-In-Time) and AOT (Ahead-of-Time) EVM
- JIT: convert bytecode to native machine code just before execution to bypass the VM’s interpretative process.
- AOT: compile the highest demand contracts and store them on disk, to avoid untrusted bytecode absuing native-code compilation.
1.13. Actor model
- A paradigm/framework for designing distributed systems.
- Actor: each actor is an independent entity to receive, process and send messages; create new actors or modify its state.
1.14. Storage trie
- Each contract account has its own storage trie, which is usually stored in a KV database.
1.15. Serverless database
- Allow developers to focus on writing queries without managing database servers.
- Automatically scales up or down base on the workload.
- Pay-per-use pricing.
2. Reth scaling plan
- Current status (April 2024): achieves 100-200 mg/s during live sync, including sender recovery, transaction execution and block trie calculation.
- The scaling plan does not involve solving state growth.
2.1. Vertical scaling (2024)
- Optimize how each system handle transactions and data.
2.1.1. JIT/AOT EVM
2.1.2. Parallel EVM
- Utilize multiple cores during EVM execution.
- <80% of historical transactions have non-conflicting dependencies.
- Historical sync: can calculate the best parallelization schedule offline; an early attempt is available.
- Live sync: combine serial and parallel execution based on static analysis, since Block STM has poor performance during heavy state contention periods; an early attempt is available.
2.1.3. Optimized state commitment
- Traditional EVM implementation couples the transaction execution and the state root computation: the state root is updated whenever a transaction updates a trie, since the state root computation has to be sequential from the updated node to the root, this is slow.
- Reth decouples the process: raw state data is stored in KV databases, and each trie is re-built for each block from the databases in the end.
- Pro: can use more efficient databases.
- Con: need to re-calculate the entire trie, which costs >75% of end-to-end block production time.
- Optimizations:
- Now already re-calculate the storage trie for each updated contract in parallel.
- Can also calculate the account trie when the storage tries are computed.
- Pre-fetch cached trie nodes (cached by the state root computation) by tracking updated accounts and storage, e.g., a part of the trie may remain the same hash.
- Going beyond:
- Only calculate the state root every \(T\) blocks.
- Lag the state root computation a few blocks behind to advance executions.
- Use a cheaper encoder and hash function (Blake3).
- Use wider branch nodes.
2.2. Horizontal scaling (2025)
- Spread the workload across multiple systems.
2.2.1. Multi-Rollup (?)
- Reduce operational overhead of running multiple rollups.
2.2.2. Cloud-Native nodes.
- Deploy the heavy node (e.g., sequencer) as a service stack that can autoscale with compute demand and use cloud storage for persistence.
- Similar to serverless database projects, e.g., NeonDB.
2.3. Open questions
- Second order effects of above changes, e.g., on light clients.
- What is the best, average and worst case scenarios for each optimization.